
June 12, 2025
General
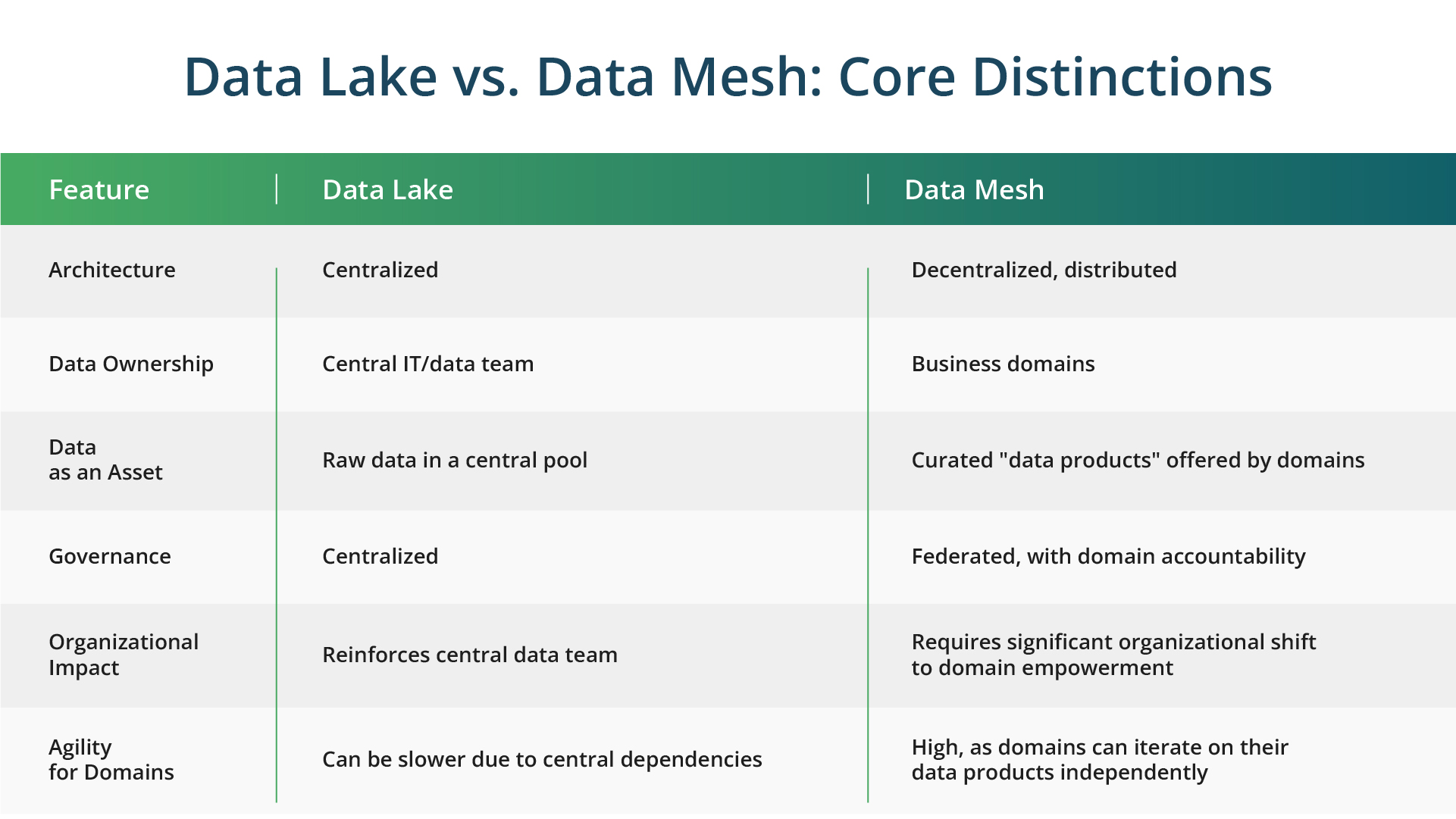
Data Lake vs. Data Mesh: Which Architecture Best Solves Your Enterprise Silos?
Businesses today are overflowing with data, yet often struggle to turn it into actionable insights. Around 402 million terabytes are created daily, and we're heading toward 181 zettabytes a year in 2026. This flood of information brings opportunities, yet it also worsens a persistent organizational problem: the enterprise data silo. These isolated data pockets hinder collaboration, hide vital insights, and reduce the agility businesses need to succeed.
In 2026, with AI and machine learning becoming increasingly dependent on high-quality, accessible data, the stakes for getting your data architecture right have never been higher. The main question now is about how to design data management to break down these silos and use its full potential. Two main architectural approaches, the data lake and the data mesh, offer different solutions. Both aim to make data more accessible, but they have different philosophies and outcomes. Picking the right approach is key to changing your data environment from a point of friction to a source of innovation.
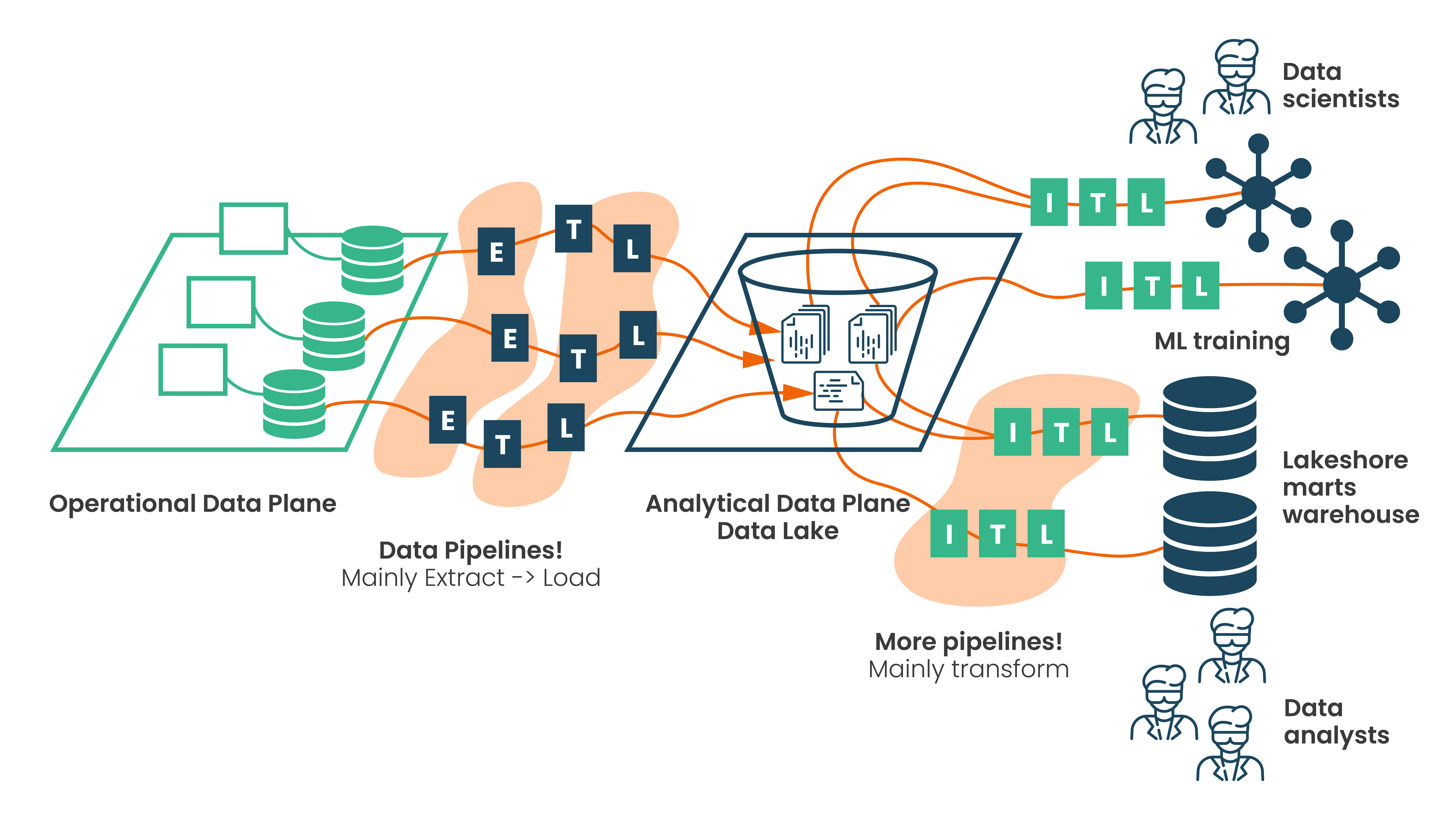 A typical data lake setup: Raw data is ingested from operations, then refined through pipelines for analytics and ML.
Source: Starburst
A typical data lake setup: Raw data is ingested from operations, then refined through pipelines for analytics and ML.
Source: Starburst
 Source: Starburst
Source: Starburst
 Source: AWS
This gave them a single database. However, as Zalando's data lake grew to petabytes in size, they ran into usual problems: managing data sharing across hundreds of teams, making sure backups and recovery were robust (S3 versioning was key here), and lowering big storage costs. They solved these by:
Source: AWS
This gave them a single database. However, as Zalando's data lake grew to petabytes in size, they ran into usual problems: managing data sharing across hundreds of teams, making sure backups and recovery were robust (S3 versioning was key here), and lowering big storage costs. They solved these by:
What is a data lake, and what are its promises and perils?
A data lake is a centralized place intended to hold enormous volumes of data in its native, raw form, structured, semi-structured, or unstructured. The central concept is "ingest now, structure and analyze later" (schema-on-read), which gives great freedom. This lets companies support different analytics, save everything, and get reasonably cheap storage. Popular data lake platforms include Amazon S3 combined with AWS Glue, Azure Data Lake Storage, Google Cloud Storage, and open-source solutions like Apache Hadoop. Many organizations also leverage modern lakehouse architectures using tools like Databricks or Apache Iceberg, which combine the flexibility of data lakes with some structured data warehouse capabilities. Though it helps to consolidate raw data for exploration, this centralized approach has certain drawbacks as well. Major, continuous work is needed in managing access, guaranteeing data quality across several sources, and keeping the lake from turning into a disorderly "data swamp." As Matthias Patzak from AWS points out in his blog, swamps cause discoverability and usability problems, as well as a bottleneck for the central crew tending the lake.
A typical data lake setup: Raw data is ingested from operations, then refined through pipelines for analytics and ML.
Source: Starburst
What is a data mesh, and how does it decentralize ownership?
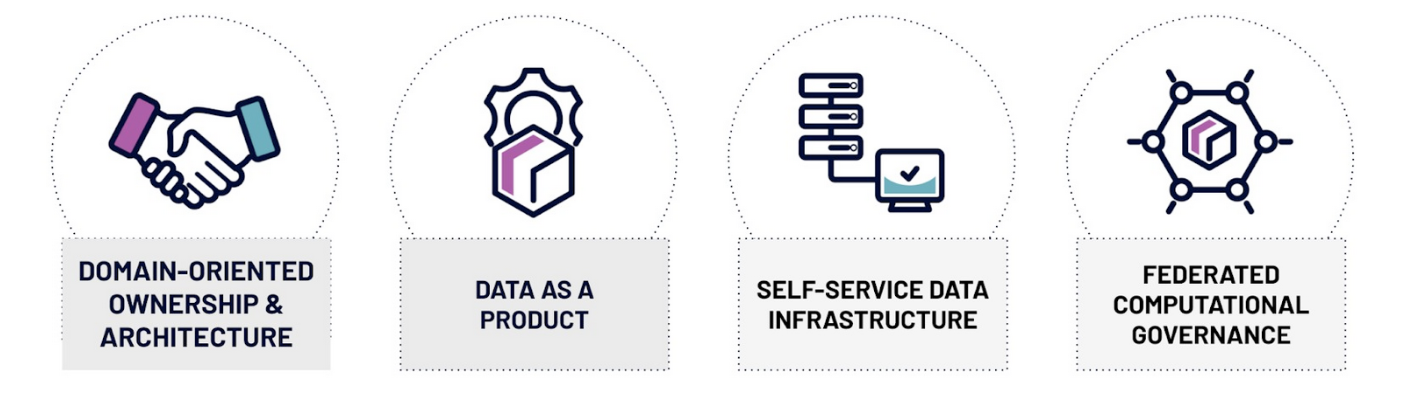
As organizations faced the limits of fully centralized models, the data mesh philosophy, started by Zhamak Dehghani, offered a new option. Instead of one huge, centrally managed lake, the data mesh pictures a distributed network of "data products" owned by different business areas. Since Dehghani first introduced the concept in 2019, data mesh adoption has grown steadily among large enterprises. Companies like Netflix, Intuit, JPMorgan Chase, and Zalando have publicly shared their journeys toward mesh-like architectures, though full implementations remain complex and require significant organizational commitment. Imagine it less like one big reservoir and more like many connected, well-kept local water sources. Each source is managed by the group (business domain) that best understands its contents. The main ideas, detailed in the ArXiv paper "Towards Avoiding the Data Mess," focus on:
Source: Starburst
- Domain Ownership: Business areas own their data.
- Data as a Product: Data is treated like a valuable product with specific users.
- A Self-Serve Data Platform: A central infrastructure that helps business areas work with data.
- Federated Computational Governance: This balances company-wide standards with the independence of each business area.
How do you align data architecture with your business?
Deciding between a data lake and a data mesh is a key choice that must fit your organization's specific situation, maturity, and goals. There's no single "better" option, only what works best for you.When a Data Lake Shows Its Value
A data lake often proves its worth when your primary needs revolve around centralized raw data storage and foundational analytics. It can be a strong asset if your organization has a robust central data team capable of managing the associated infrastructure and governance.Prioritizing Cost-Effective Storage Over Complex Sharing
The data lake model also fits well if the immediate priority is cost-effective storage for diverse raw data, taking precedence over intricate, real-time data sharing across different business domains. For smaller organizations, or those where a shift to fully independent domain data ownership represents a significant cultural or operational leap, it serves as a practical first step.When Centralization Limits Become Apparent
However, if your enterprise is grappling with the limitations of centralization, a data mesh becomes an attractive option. If central data teams are causing delays, slowing innovation, and hindering the release of data-driven features, this is a key signal.Leveraging Deep Domain Knowledge
A data mesh also supports scenarios where deep, domain-specific knowledge is vital for extracting the real value, quality, and context from your data, empowering these experts directly.Addressing Silos and Accountability
If widespread data silos are blocking cross-functional teamwork and a complete business overview, or if establishing clear accountability for data quality across different business areas is crucial, the data mesh principles of domain ownership and "data as a product" offer a clear way forward.Suiting Large, Agile Organizations
Data mesh architecture is particularly well-suited for large, complex organizations already employing distributed, agile teams. These teams could significantly gain from more data independence and the ability to quickly update their own data products. As this ArXiv paper highlights, a certain degree of domain focus and a dedication to improving data governance and platform abilities are necessary for a successful data mesh adoption.
Data Lakes Within a Data Mesh: Can You Have the Best of Both Worlds?
Building a data system isn't always an either/or choice. More and more, companies see that data lake and data mesh ideas can work together and even improve each other:- A data lake can serve as a technology component within specific domains in a data mesh, acting as the storage layer for its raw data before it's refined into a data product.
- The self-serve platform in a data mesh might offer data lake-like storage services (e.g., object storage) that domains can consume.
- Even with a primary data lake, applying "data as a product" thinking can significantly improve its organization and usability.
A Real-World Glimpse: Zalando's Data Lake Evolution
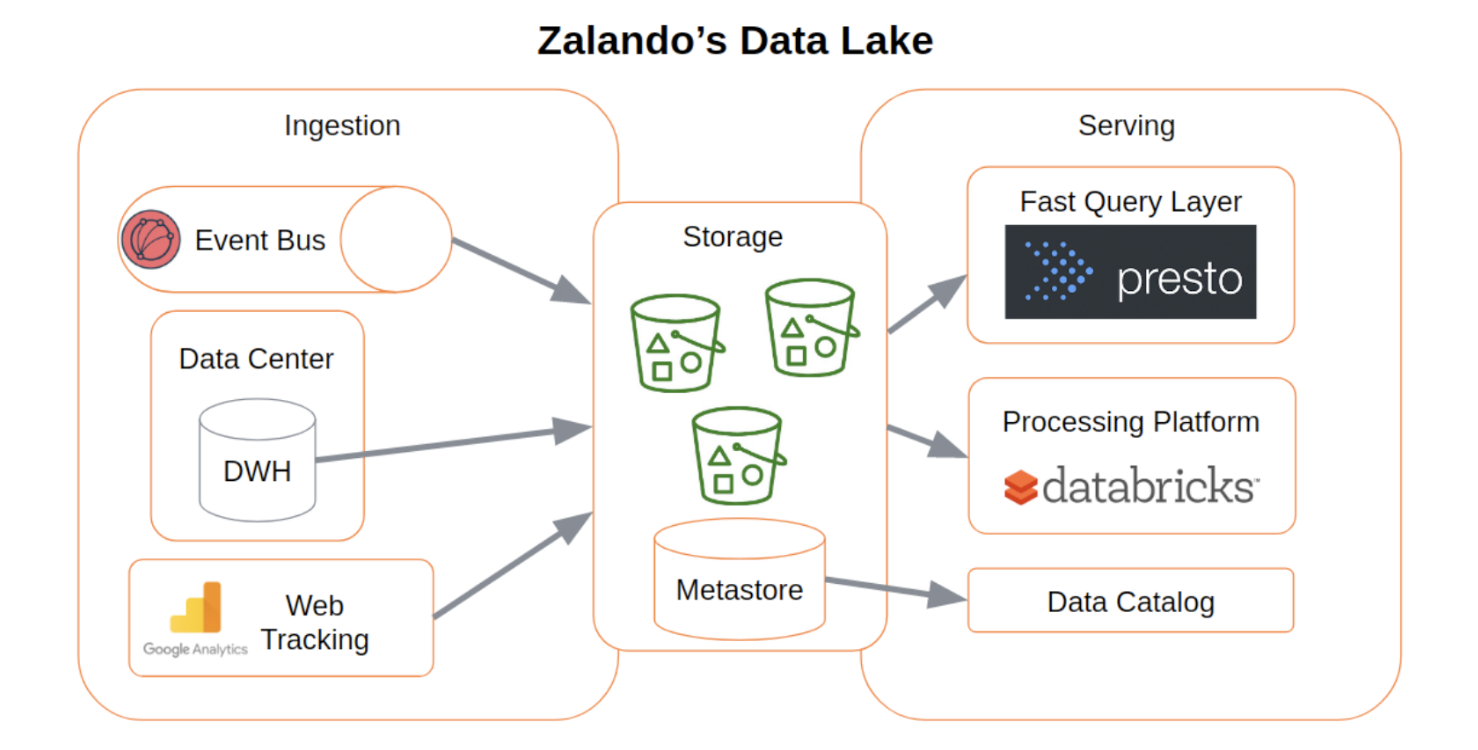
Zalando, Europe’s top online fashion platform, shows a real example of how a data lake works. Around 2015, Zalando moved from an old, single system to a cloud-based data lake on Amazon S3. This happened because they needed to handle growing data complexity while supporting analytics in their changing microservices setup. Important parts of their first data lake setup included:- Main Goals: Create a central place for data and a distributed system to process it.
- Where Data Came From:
- A central event bus (getting data from microservice communications).
- Old Data Warehouse (DWH) data sets (with sales rules).
- Lots of web tracking data.
Source: AWS
This gave them a single database. However, as Zalando's data lake grew to petabytes in size, they ran into usual problems: managing data sharing across hundreds of teams, making sure backups and recovery were robust (S3 versioning was key here), and lowering big storage costs. They solved these by:
- Cost & Lifecycle Management: Using S3 Inventory and S3 Access Logs to see how data was used. Also, they made use of S3 storage classes (Standard-IA, Glacier) with S3 Intelligent-Tiering and lifecycle policies.
How Can Kanda Help
Our expertise in modern cloud data solutions, along with our understanding of effective DevOps strategies and platform engineering, allows us to help your enterprise in several ways:- Evaluate your current data situation and define the most suitable architectural direction.
- Design and implement scalable, governable data platforms, whether lake, mesh, or hybrid.
- Support the necessary organizational and cultural changes vital for success, especially with a data mesh.
- Develop high-value data products that produce tangible business results.
Conclusion
The choice between a data lake and a data mesh is a strategic one, closely linked to your organization's unique situation, maturity, and goals. Before committing to either approach, assess your organization’s data literacy levels, existing technical infrastructure, and willingness to embrace cultural change—these factors often determine success more than the architecture itself. The key is to select a system design that not only solves your current data silo challenges but also helps your company use data as a key asset for ongoing growth and new ideas. Stay ahead of the curve with Kanda.Related Articles

How to Turn Your Broken Data Workflows Into Scalable Data Pipelines: An Ultimate Guide
Key Takeaways Workflows break at scale not because of selecting wrong tools, but because project-level habits, manual handoffs, copy-pasted scripts become the operating model. The architecture patterns that enable scalability: decoupled storage and compute, deliberate data layering, and orchestration treated as a control plane. Pipeline reliability is a delivery problem too. Version control, CI/CD, and…Learn More
Custom AI Development vs Off-the-Shelf Solutions: What Delivers Better ROI?
Key Takeaways Custom AI development costs more upfront but delivers stronger long-term ROI, especially for core business functions. Off-the-shelf tools get you started fast, but subscription costs scale quickly, and vendor lock-in is a real risk. Over 80% of AI projects fail, and the most common reason isn’t the technology, it’s misalignment between the solution…Learn More
Low-Code, No-Code, or Custom Build? How Enterprises Should Actually Decide
Key Takeaways Low-code accelerates app development for professional developers; no-code empowers non-technical users to build on their own. Custom development costs more upfront but offers full control over security, scalability, and integration. Hidden costs like vendor lock-in, licensing at scale, and security gaps can erode the savings platforms promise. Most successful enterprises use a hybrid…Learn More
Why Using Edge AI for Real-Time Analytics Is Your Next Best Decision
Key Takeaways: Edge AI processes data locally in 1–10 ms, compared to 50–200 ms with cloud-based analytics, making it critical for time-sensitive operations. Organizations can cut data transmission costs by up to 43% and reduce cloud-bound traffic by over 90% by filtering data at the edge. Industries like manufacturing, healthcare, autonomous vehicles, and smart cities…Learn More

