
The Future of Drug Development Runs on Omics Data Platforms
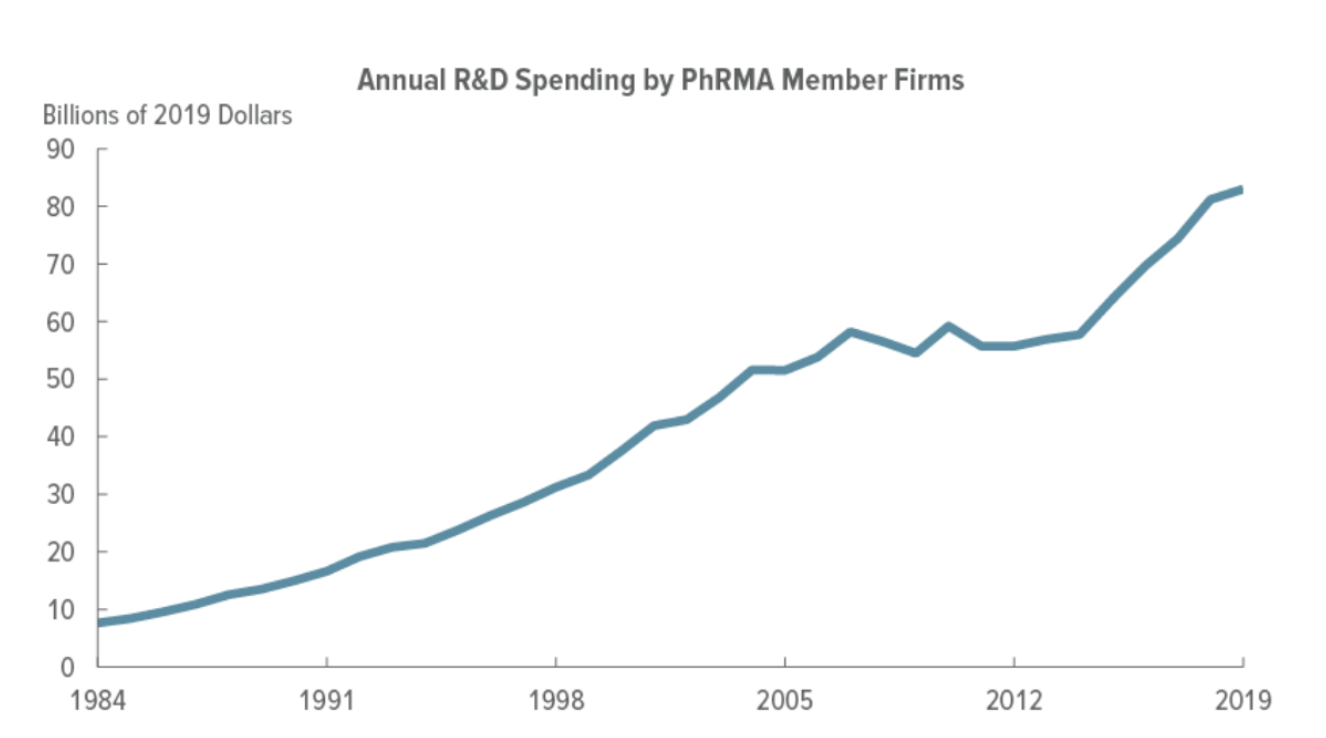
Traditional drug development is running into a serious efficiency problem. Getting a new medicine to market now takes more than ten years and costs well over $2 billion on average, according to a recent study. Even though scientific breakthroughs keep arriving, the expense of R&D keeps climbing faster than the number of new approvals, a paradox often called “Eroom’s Law.” The old model, with its long timelines and high drop-out rates, is becoming hard to justify.
The industry must find a different way to meet the expectations of personalized treatment and to tackle diseases that involve many moving parts. Relying on the classic playbook won’t get us there. What we need is a strategy that leans on data and embraces the full complexity of human biology. Omics data platforms supply the technical backbone that can turn huge biological data sets into therapies that actually help patients.
Why does drug development demand a new approach?
The “one-size-fits-all” view of medicine is losing relevance.
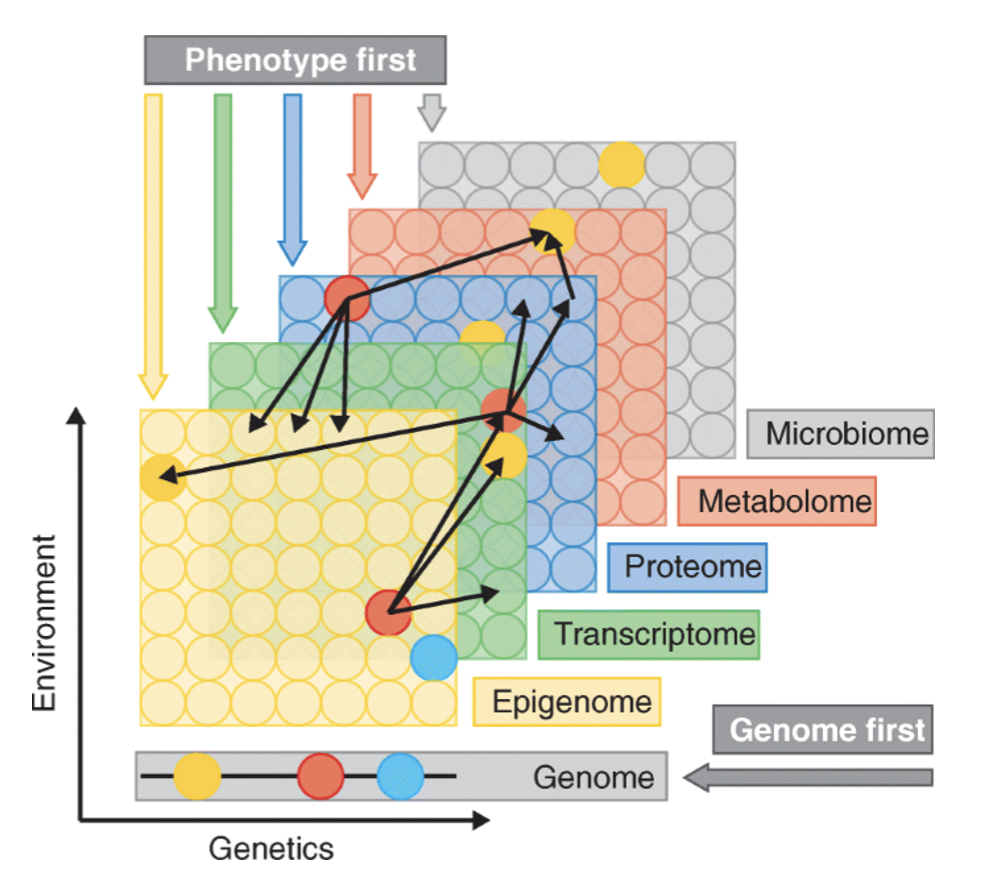
Precision medicine and targeted therapies demand a deeper look at the molecular roots of disease. Most illnesses are not caused by a single faulty molecule; they arise from a tangled network of genes, proteins, and metabolites. Traditional research methods often miss this web, which leads to drug candidates that stumble in clinical trials because they either don’t work well enough or raise unexpected safety concerns.Multi-omics, the combining of genomics, transcriptomics, proteomics and metabolomics, offers a way forward.A review in Proteomes points out that this integrated view gives a more complete picture of biological systems, moving past the limits of studies that focus on just one layer. By stacking different types of data, scientists can pinpoint drug targets with greater precision, sort patients into more meaningful groups, and forecast how treatments will perform.
What are omics data platforms and how do they reshape research?
Think of the human body as a bustling city. As this Medium article puts it, Genomics is the master plan for every building, transcriptomics shows which plans are being used right now, proteomics describes the workers and machines inside those structures, and metabolomics tracks the resources flowing through the streets.
The promise of this information is huge, but the sheer volume, variety, and intricacy create massive obstacles. Data points are often scattered across separate systems, lack consistent metadata, and come in formats that don’t talk to each other. Pulling useful, cross-functional insights from such a mess is almost impossible.
An omics data platform is the infrastructure that brings order to the chaos. It is more than a storage vault; it is an integrated environment that can ingest, process, and analyze multi-omics data at scale. The platform supplies a toolbox that supports every step of drug discovery from loading raw files to generating actionable insights. Its ultimate aim is to become a single source of truth that makes complex data findable, accessible, interoperable, and reusable (FAIR).
How Omics Platforms Speed Up Discovery and Deliver Returns
By gathering and harmonizing tangled biological data, omics platforms attack the core inefficiencies of the old R&D pipeline. They shave time off projects, raise the quality of candidate molecules, and cut the financial risk of late-stage failures.
Revolutionizing Target Identification and Validation
The first stage of drug discovery is to locate a molecular target, which is a gene or protein linked to a disease. In the past, researchers manually combed through literature to find these clues. Modern omics platforms, especially when paired with AI and machine learning, automate and deepen that hunt. An article in Quantitative Biology shows that AI can sift through multi-omics data, spotting patterns and relationships that are invisible to the human eye, and then suggest novel biomarkers and drug targets.
By merging genomic, transcriptomic and proteomic information, teams can:
- Boost confidence in targets: Overlapping signals across layers give stronger proof that a target truly drives the disease.
- Lower false positives: Cross-validation across data types filters out noise, making findings more reliable.
- Reveal complex mechanisms: The analysis can map how genetic changes ripple through proteins and metabolic pathways, offering a fuller view of disease biology.
Economic Impact: Cutting Costs and Shortening Timelines
Most of the money spent on drug development goes into clinical trials, and a failure at that stage can be financially devastating. Improving the quality of candidates before they reach patients can dramatically lower those failure rates. An analysis by PharmTech estimates that a 20 % drop in clinical-phase failures could save hundreds of millions of dollars for each approved drug.
Companies that have adopted these technologies are also moving faster. AI-first startups have shown they can push molecules into clinical testing in a fraction of the usual time. For instance, Deep Genomics identified a new target and candidate for Wilson’s disease in under 18 months, a timeline that would normally span several years. Faster progress means lower development costs and a quicker route to market.
A Real-World Example: Kanda’s Platform for a Large Pharma Partner
Building a truly useful omics platform is a complex project. To illustrate what success looks like, consider the end-to-end analytics platform Kanda recently delivered for a major pharmaceutical client. The partner struggled with hundreds of reference datasets spread across many locations, which slowed decision-making.
Kanda’s solution was a unified system built around four custom components, each designed to create a single, standardized data ecosystem:
Annotator
Replaces manual, error-prone tagging with an automated workflow. By centralizing metadata under a controlled vocabulary, it guarantees that every dataset is consistent, searchable and ready for integration.
Visualization Platform
A web-based, interactive app that lets scientists explore complex data through heatmaps, network graphs and other visual tools. Turning raw numbers into clear pictures helps generate new hypotheses quickly.
Data Transfer Manager
A user-friendly web application that automates secure exchanges with external labs. It enforces best-practice protocols, reduces mistakes and eases the burden on data managers.
Single-Cell Data Tracker
Maintains a real-time catalog of publicly available and internally generated single-cell datasets. It continuously aggregates new data and intelligently merges duplicates, saving time and preventing redundancy.
The result was a cohesive, standardized data environment that gave the client deeper insights and a faster research workflow.
Overcoming Common Hurdles: Integration, Security and Scale
The promise of omics platforms is clear, but putting them into practice brings several challenges. Legacy systems must be linked, data privacy must be protected, and the architecture has to grow with ever-larger datasets.
Data fragmentation remains the biggest obstacle. The Institute for Experiential AI notes that silos hide valuable patterns and make it hard to reproduce or scale findings. A successful platform must not only gather data but also harmonize it, standardizing formats and applying consistent metadata throughout.
Security and compliance are non-negotiable. Omics data often includes sensitive patient information, so platforms need robust access controls and must meet regulations such as HIPAA and GDPR.
Scalability is essential as data volumes explode. Cloud-based services like
Amazon Omics are emerging to provide flexible, on-demand infrastructure that can store and analyze petabytes without the overhead of managing physical hardware. Kanda has extensive experience building secure, scalable digital health solutions that meet these demands.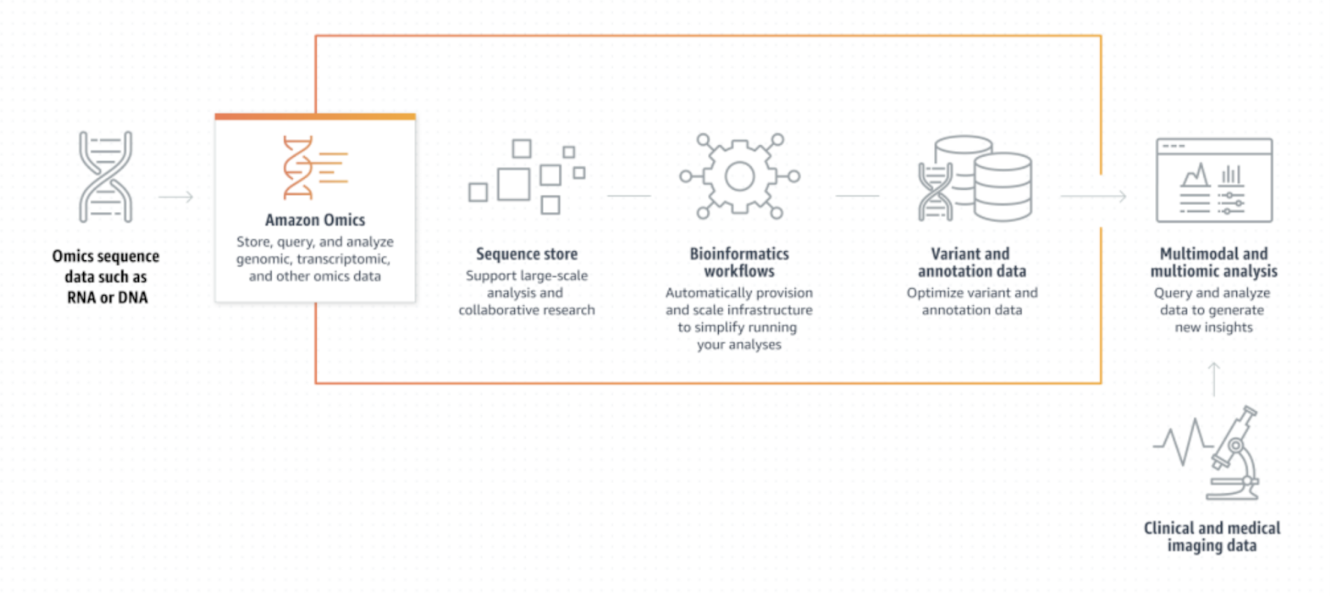
What does the next decade of drug development hold?
The marriage of omics platforms and artificial intelligence is set to reshape the industry further. AI and machine learning are no longer buzzwords; they are practical tools for extracting meaning from high-dimensional data. We are already seeing a shift from basic machine learning models to deep learning architectures that can capture nonlinear relationships across multi-omics layers, producing more accurate predictions of disease risk and treatment response.
Advances in AI for clinical image analysis and natural language processing will also matter. By linking unstructured data such as physician notes and scientific papers with structured omics information, researchers will obtain a truly comprehensive view of each patient. As these healthcare software development trends continue, the drug development lifecycle will become faster, more precise, and more productive.
How Kanda Can Help
Designing, building and rolling out a custom omics data platform involves many moving parts: merging old systems, guaranteeing security, and reconciling inconsistent data formats. These tasks require deep technical expertise and strategic planning, resources that many life science organizations find hard to allocate. Partnering with a team that specializes in custom software development can bridge that gap.
- Build Custom Omics Platforms: We design and implement secure, scalable, compliant platforms that manage the full lifecycle of multi-omics data.
- Manage Legacy System Integration: We create robust transformation pipelines that harmonize siloed datasets and bridge old infrastructure with modern analytics.
- Develop Interoperable Applications: We build intuitive tools from annotation utilities to advanced visualization dashboards so scientists can explore data and move discovery forward.
- Ensure Security and Compliance: We engineer to meet regulations like HIPAA and GDPR, with access controls and safeguards that protect sensitive biological and patient data.
Talk to our experts to learn how a tailored omics platform can transform your drug-discovery workflow, turning massive data sets into the next generation of precision therapies.
Conclusion
Turning the complexity of human biology into effective treatments is the next big unlock. The linear R&D model isn’t built for that job. Omics data platforms make the shift possible by grounding discovery in integrated data and analytics. With multi-omics and AI working together, teams can find better targets, design stronger candidates, and move through development with fewer surprises.
For pharma and biotech, the question isn’t whether to adopt this approach but how to implement it well. The advantage goes to organizations that can bridge legacy systems to a modern, integrated data environment while keeping that environment usable, secure, and scalable as the science moves forward.
Related Articles

Scaling Biotechnology Software Development: From Research Prototypes to Enterprise-Grade Solutions
Biotech never stops moving forward, but turning a lab breakthrough into a product ready for the market is anything but straightforward. A key piece of that transition, which is often missed, is the evolution of the software behind the science. The flexible, one-off tools used in early experiments, often a collection of ad-hoc scripts, shared…Learn More
Computational Neuroscience Simulations: Combining Science and Technology
The human brain is an astonishingly complex network of approximately 86 billion neurons forming trillions of synaptic connections, making it one of science's biggest puzzles. Understanding its intricate functions is a huge undertaking. Computational neuroscience simulations are now a central way to bring together advanced scientific research and the latest technology to approach this challenge.…Learn More
Applications of Computer Simulation Software in Medicine and Pharmaceuticals
Getting new treatments into the hands of patients is a scientific challenge, and a financial one too. According to a JAMA Network Open study, the average cost to develop a new drug in the U.S. was around $879 million between 2000 and 2018. The same study notes that other research places the R&D cost for…Learn More
Systems Biology Modeling Software for Researchers: The Hidden Value
Computational modeling has grown into a crucial resource for researchers who aim to understand how living systems function. According to Bioinformatics Advances, “Computational models are now approaching the complexity required to simulate full human systems — from single cells to entire organs — enabling in silico experiments for treatment prediction and disease modeling.” This milestone…Learn More

