
February 04, 2026
Healthcare
The Good, the Bad, and the Ugly of Synthetic Healthcare Data
Key Takeaways:
 Source: The HIPAA Journal
Source: The HIPAA Journal
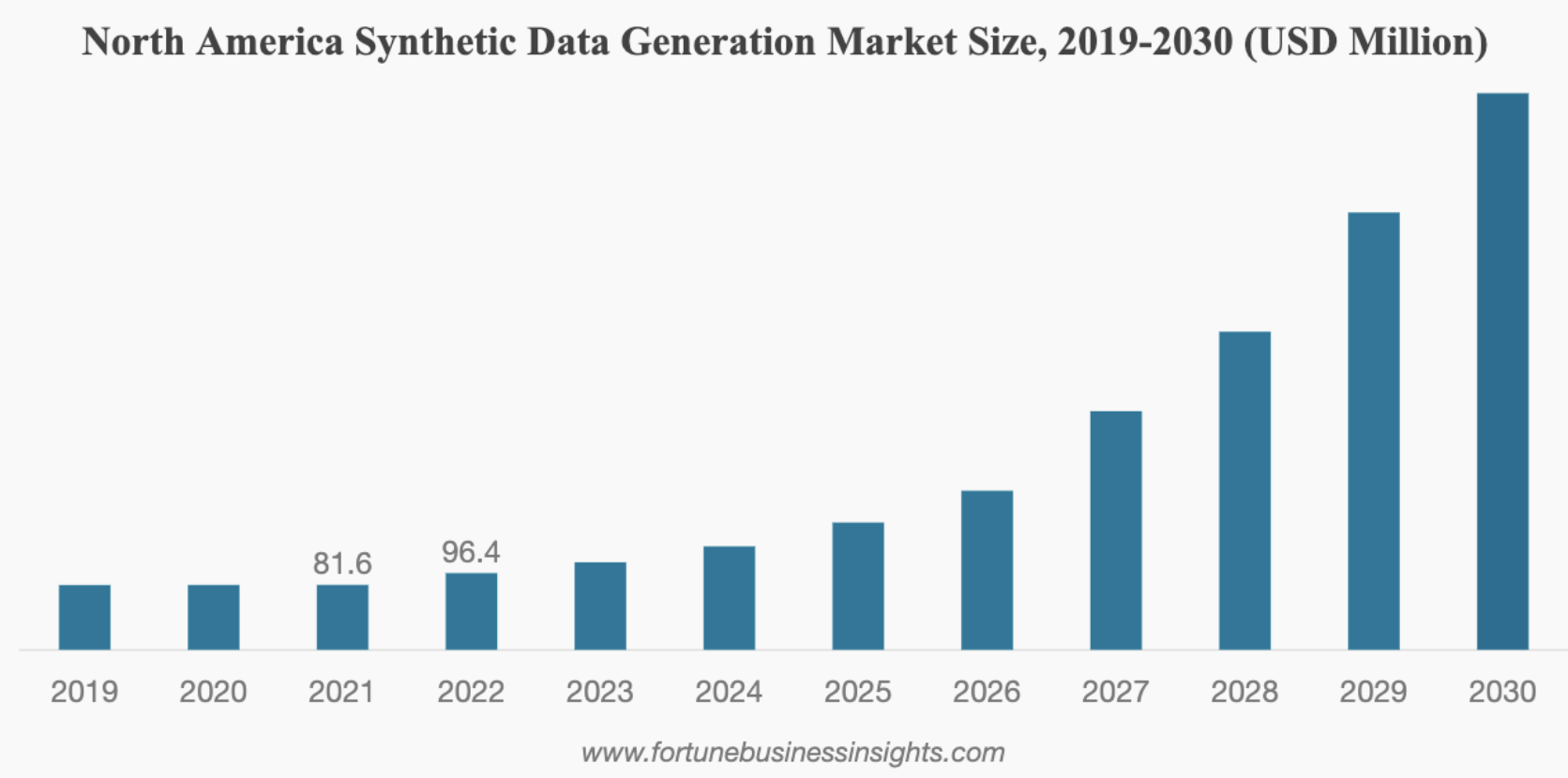 Source: Fortune Business Insights
Source: Fortune Business Insights
- Synthetic healthcare data creates statistically realistic "fake" patient records that bypass HIPAA restrictions while enabling AI development and research.
- Major benefits include unlimited scalability for rare diseases, cost reduction in data acquisition, and faster development cycles without privacy concerns.
- Critical risks include bias amplification, unvalidated statistical accuracy, and regulatory uncertainty around clinical use.
- Real patient data remains mandatory for FDA submissions, clinical validations, and legal proceedings—synthetic data is a supplement, not a replacement.
Source: The HIPAA Journal
What Synthetic Healthcare Data Actually Means
Synthetic healthcare data is information generated by a computer to serve as real patient files. This realistic synthetic data has the same statistical properties and characteristics as real data, but there isn't actual patient data included. Whether it's tabular data from electronic health records or other medical data formats, it is important to know how this is different from other types of data. Anonymized data is generated from real patients. You just take a real record and remove names or ID numbers. The problem is that the underlying info still belongs to someone. Synthetic data is different because it creates entirely new, fictional patients from scratch. These "patients" follow the same trends and correlations you’d find in a real hospital, but no synthetic patient matches up with a real human being. There is also "fabricated" data, which is just random and doesn't follow any rules. Synthetic data is the middle ground: it’s fake, but it’s smart enough to be useful for real research.The Generation Process Behind Synthetic Medical Records
There are a few steps to making high-quality synthetic healthcare data. First, algorithms look at the input data from real healthcare records to figure out how it works and to identify specific patterns that need to be replicated. When working with tabular synthetic data for example, the algorithms analyze how data points are distributed, meaning, they look at how diagnoses are spread out across age groups, how lab values and outcomes are related, and how chronic diseases usually get worse. This approach gets the "DNA" of the original dataset without keeping track of each entry. After that, the process of generating synthetic patients begins as generative models use those patterns to build new records with realistic physiological data. For instance, the system might create a 67-year-old man who has Type 2 diabetes and an A1C of 7.8%. This person doesn't actually exist; the computer just knows that this specific combination of age and health markers is something that would realistically happen based on the original data it studied. The final result gives you the big-picture insights of a whole population, but it removes the risk of someone being identified.The Good: Benefits That Make Synthetic Data Attractive
People are excited about synthetic data for good reasons. When it’s done right, it solves a lot of the major challenges in medical research and software development.Privacy Compliance Without Compromising Research
Because synthetic data isn't tied to real people, it doesn't fall under the strict data privacy regulations of the Health Insurance Portability and Accountability Act (HIPAA) for Protected Health Information (PHI). This eliminates concerns about data leakage and privacy breaches. This is a game-changer because it means companies can enable data sharing with outside researchers or partners without spending months signing legal contracts or waiting for privacy boards to give them the green light. The National Institutes of Health showed how well this works during the COVID-19 pandemic. They worked with a company called Syntegra to create millions of synthetic patient records. This allowed scientists to collaborate almost instantly, which would have taken far too long, when time was of the essence, if they had tried to share real, protected patient data.Unlimited Scalability for AI Training
AI models need a lot of training data, and healthcare often doesn't have enough. If you’re looking at a rare disease, there might only be a few hundred cases to study. Or maybe certain groups of people aren't represented well in the records. These gaps make it hard to train a trustworthy AI. Synthetic data can fill those gaps through data augmentation and supplement existing datasets. For example, the University of Florida worked with NVIDIA to build SynGatorTron. This is a model that creates synthetic patient profiles to augment datasets for rare diseases. This helps developers build predictive models that can handle all different types of "edge case" scenarios that don't happen every day.Cost Reduction in Data Acquisition
Getting real healthcare data is incredibly expensive. You have to pay for patient recruitment, set up the tracking infrastructure, and pay licensing fees. It adds up fast. Synthetic data changes the math. Once you have the system set up for generating synthetic data, making more of it becomes pretty cheap. Fortune Business Insights expects the synthetic data market to jump from $351 million in 2023 to over $2.3 billion by 2030, mostly because companies are looking for these cheaper options.Source: Fortune Business Insights
Testing and Development Freedom
Developers who build healthcare apps are usually stuck in a loop: they need realistic data to see if their apps work, but they can't get to the real patient data because of security risks. Synthetic data solves this paradox. Dev teams can use these realistic sets as test data to test their code and validate their systems. Washington University School of Medicine used a synthetic data platform called MDClone to do exactly this. It allowed their researchers to get the data they needed in minutes, rather than waiting weeks for the traditional approval process.The Bad: Limitations That Demand Attention
Synthetic data isn't a magic fix for everything. You have to know its limits if you want to avoid making expensive mistakes.Statistical Accuracy Isn’t Guaranteed
The data quality of synthetic data is only as good as the model that made it and the training data that feeds it. Producing high quality synthetic data requires careful validation and testing. If the process is flawed, the synthetic samples might have errors or miss important connections. It might look right on the surface but give you the wrong answer when you try to run a study or perform data analysis. Small but vital details often get lost. Things like how two specific medications interact or how a rare disease slowly gets worse might not make the jump from real data to synthetic data. A study in PLOS Digital Health pointed out that we don't even have a standard way to check if synthetic data is "good" yet, which is a concern when people's health is on the line.Bias Amplification Risks
The biggest worry is that synthetic data can make existing biases worse. If the original data mostly comes from one group of people, the synthetic data will do the same and might even exaggerate the gap. A study in Health Affairs found that while computers can "rebalance" data to make it look fairer, they often just end up hiding the old biases. For example, researchers found that when algorithms used risk scores to select patients for care management, only 17% of the eligible were people of color. This happened because the training data was biased from the start.Rare Event Representation Problems
Most algorithms are designed to find the "average" or "most common" patterns. This means they often ignore rare occurrences. Things like an atypical reaction to a drug or an unusual way a disease shows up might get deleted during the generation process. In a hospital, those rare "edge cases" are often the most important ones to get right.Validation Challenges and Uncertainty
How do you know for sure that the fake data matches the real world? To check it, you have to compare it back to the real data. This creates a bit of a loop. You have to find a way to trust the synthetic set without accidentally leaking the privacy of the real patients you’re comparing it to. Studies in JMIR Medical Informatics have shown that synthetic data can produce results similar to real data, but we still haven't seen enough of these studies to be 100% sure across the board.Regulatory Uncertainty and Acceptance Issues
Regulatory bodies haven't fully decided how to handle synthetic data for things like new drug approvals. The FDA is interested, but they haven't given any clear "how-to" guides yet. As the Clinical Trial Vanguard noted, no major drug has been approved based just on synthetic data.The Ugly: Real-World Realities and Hard Truths
Not a Complete Replacement for Real Data
Despite what some marketing teams might say, synthetic data isn't going to replace real patient info anytime soon. If you’re submitting a final clinical trial or tracking how a disease is spreading through a city, you still need the real thing. Synthetic data is a great helper, but it’s not a substitute.Technical Complexity Creates Barriers
Making good synthetic data isn't easy. You need data scientists who understand both electronic health records and high-level data science. Many companies just don't have those people on staff. If you implement it poorly, you might end up with a dataset that looks fine but leads to dangerous conclusions.The “Black Box” Problem in Generation
Some of the methods used to make this data, like generative adversarial networks (GANs), are basically "black boxes." Even the people running them can't always explain exactly how the computer came up with a specific result. This makes it hard for doctors or regulators to trust the data.Market Hype Versus Clinical Reality
There is a big gap between what companies promise and what actually works in a clinic. Gartner once predicted that 60% of AI data would be synthetic by 2024. While that number is popular in marketing materials, hospitals are moving much slower because they know the risks are high.Synthetic Data Generation Methods in Healthcare
Statistical Modeling Approaches
These are the traditional methods. They look at how the data is spread out and try to copy it. They are easy to explain and don't require massive computers, but they struggle with complex, "messy" data.Machine Learning and Deep Learning Techniques
These machine learning models use newer tech like generative adversarial networks (GANs) or transformer models. They are great at finding hidden patterns in huge amounts of data and can create new data that closely resembles the original. The downside is they take a lot of power to run and are hard to explain.Hybrid and Specialized Healthcare Methods
Some tools combine different methods. For example, a technique called synthetic minority oversampling technique (SMOTE) helps balance out data when there aren't enough rare cases. Synthetic data generation tools like the open-source Synthea platform can create long-term patient histories based on medical guidelines, while platforms like MDClone turn real hospital records into synthetic versions.When Synthetic Healthcare Data Works Best
Synthetic data is really useful for:- Building and testing an algorithm before you get access to real hospital records.
- Sharing data with outside partners or researchers without breaking privacy laws.
- Adding more examples of rare diseases or underrepresented groups to existing datasets.
- Creating test data for software developers and QA testers.
- Using data for teaching and medical education.
- Doing a "quick check" to see if a clinical trial is worth the money.
- Making sure a dataset has a diverse mix of people.
When Real Data Remains Necessary
You still need real patient information for:- Sending final trial results to the FDA or other regulators.
- Checking if a diagnostic tool actually works before using it on patients.
- Tracking real-world health trends in a population.
- Testing how a new medical device performs.
- Figuring out insurance payouts and reimbursements.
- Any kind of legal case or official audit.
Best Practices for Implementing Synthetic Healthcare Data
If your organization is thinking about using synthetic data, keep these points in mind:Start with Clear Objectives and Use Case Definition
Don't just make data for the sake of it. Figure out exactly what problem you are trying to solve. Start with a small pilot project to see if it actually works before you go all-in.Validate Rigorously Before Use
You need to double-check that the synthetic data’s stats match the real world. Have doctors check the clinical data results to make sure they make sense. Just because the math looks right doesn't mean the medical side is accurate.Maintain Real Data Infrastructure
Don't throw away your real data systems. You’ll still need them for validation and meeting regulatory rules. Synthetic data should be an extra tool, not the only tool.Document Generation Methods and Limitations
Be honest about how you made the data and where it might be weak. If someone is using your dataset, they need to know it's synthetic and what it should (and shouldn’t) be used for.How Kanda Can Help
Setting up synthetic data requires a mix of data science, and legal understanding. Kanda has been working in healthcare tech for decades, and we can help you figure out if synthetic data makes sense for you. We can help with:- Checking if synthetic data fits your specific goals.
- Setting up the tech to generate the data within your current systems.
- Building frameworks to make sure the data is high quality and follows the rules.
- Using synthetic data to train AI models that actually work in a clinical setting.
- Helping you navigate the changing rules and regulations.
Conclusion
Synthetic healthcare data has a lot going for it. It protects privacy, it scales easily, and it can save a lot of money. For certain jobs, it's incredibly valuable. But it isn't perfect. It has issues with accuracy, it can be biased, and the rules around it are still being written. If you use it without understanding these flaws, you could end up with bad research or algorithms that don't work on real people. The best way forward is to be honest about what this tech can and can't do. It’s a powerful tool, but it doesn't mean you can stop being careful. Success comes from using it for the right reasons, checking the results constantly, and keeping your real-world data systems healthy. Synthetic data is a great piece of the puzzle, but it isn't the whole picture.Related Articles

CMS Prior Authorization Rule 2026: What Health Systems and Payers Actually Need to Build by October 2027
Key Takeaways The 2026 CMS Prior Authorization (CMS-0062-P) rule extends electronic prior authorization requirements to drugs for the first time, closing a major gap left by the 2024 rule. The hard compliance deadline is October 1, 2027 - by that date, systems must be live, not in development or testing. Compliance requires three major technical…Learn More
Unlocking Actionable Insights from Medical Data with Clinical NLP
Key Takeaways Clinical NLP extracts useful details from notes, reports, and other free-text records so teams can work with them. The clearest use cases include coding support, trial matching, safety monitoring, registry work, and population health. The output is only useful if it connects to the standards healthcare teams already use: SNOMED CT, RxNorm, LOINC,…Learn More
Why Omics and Clinical Data Integration Remain a Challenge and How to Fix It
Key Takeaways Omics and clinical data often remain separate, making them harder to use together than they should be. The main challenge is usually not the data itself, but the mismatched formats, siloed systems, and disconnected teams surrounding it Addressing that requires robust infrastructure, shared standards, and workflows that hold up without constant manual intervention.…Learn More
AI Copilots in Healthcare: Minimizing Diagnostic Risks With Smart Virtual Assistants
Key Takeaways AI copilots act as always-on virtual assistants managing documentation, triage, and decision support so clinicians can focus on patients. With 12 million diagnostic errors and up to 80,000 deaths annually, AI copilots are built to catch what overloaded clinicians miss, not replace them. Dragon Copilot saves clinicians around 5 minutes per encounter with…Learn More

